Measure Real Engineering Output.
One bad engineer costs $100K+/yr. This finds them. Stanford-backed AI scores real output from your git history — not LOC, not story points, not gut feel.
No payment required. Your source code never leaves your environment.
70
Real Java Commits Validated
99%
Faster Than Manual Review
Stanford
Peer-Reviewed Research
We are a proud

P10Y Reseller
The Research
Validated by Stanford Research
An evidence-based alternative to LOC, story points, and gut feel — backed by Stanford and applied by P10Y.
01
Validated with Real Code, Not Theory
Seventy real Java commits analyzed by ten experts to establish a ground-truth evaluation benchmark.
02
Grounded in Stanford Research
Trained on reviews by senior software professionals using structured, peer-reviewed evaluation criteria.
03
Expert-Level Code Review, Powered by AI
AI models now mirror expert code assessments — in seconds, not hours.
04
Beyond LOC & Story Points
Traditional metrics fall short. AI estimation correlates significantly better with real development effort.
05
99% Faster Than Manual Review
Expert-level insights in under one second per commit — at the scale of your entire git history.
06
Applied by P10Y, Informed by Stanford
An approach actively deployed by P10Y and grounded in Stanford's peer-reviewed research.
The Product
What the Assessment Reveals
Four capabilities that replace guesswork with data.
Feature 01
Internal & Industry Benchmarking
A universal, tech-agnostic output metric lets you benchmark your team's performance against global peers and against itself over time.
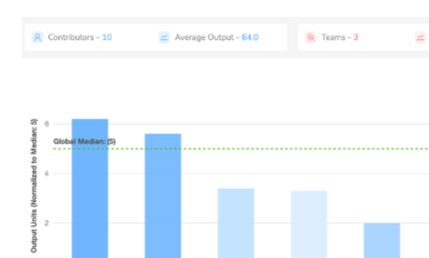
Feature 02
Based on Stanford Research
Scientifically-validated software productivity insights — not heuristics, not story points, not lines of code.

Feature 03
Real-Time & Historical Insights
See current performance in real time and measure the downstream impact of decisions you made months or years ago.
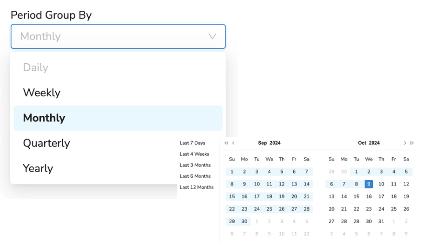
Feature 04
Cloud & On-Prem Versions
Deploy to our cloud or install on-prem for heightened security needs. Your source code never leaves your environment.
Who It’s For
Target Audience & Use Cases
Target Audience
Software companies optimizing engineering teams
M&A requiring technical due diligence
Companies selecting outsourcing partners
Teams managing performance and benchmarking
Businesses doing advanced analytics and tool ROI
Companies with remote, hybrid, or office setups
Decision-makers making refactoring decisions







Use Cases
- 01
Optimize Team Size
- 02
M&A Technical Due Diligence
- 03
Manage Team Performance
- 04
Internal & External Benchmarking
- 05
Advanced Analytics and Tool ROI
- 06
Remote, Hybrid, or Office Work
- 07
Refactoring Decisions
Pricing
Per-Person Monthly Plans
One bad engineer: $100K+/yr waste. This: from $35/person/mo. 14-day free trial.
Team
Up to 10 people
$50/person/mo
- Full productivity scoring
- Internal benchmarking
- Cloud or on-prem
Department
11-50 people
$45/person/mo
- Everything in Team
- Industry benchmarking
- Historical trends
Enterprise
50+ people
$35/person/mo
- Everything in Department
- Dedicated support
- Custom integrations
14-day free trial on all plans. Annual billing: 2 months free.
Get Started
Try Free for 14 Days
Tell us about your team. We’ll show you what we’d measure and what the benchmark looks like for a team like yours.